
Human Feedback vs. Automated Metrics in LLM Evaluation
Human feedback captures nuance, tone, and safety while automated metrics deliver fast, scalable checks—combine both for reliable LLM evaluation and monitoring.

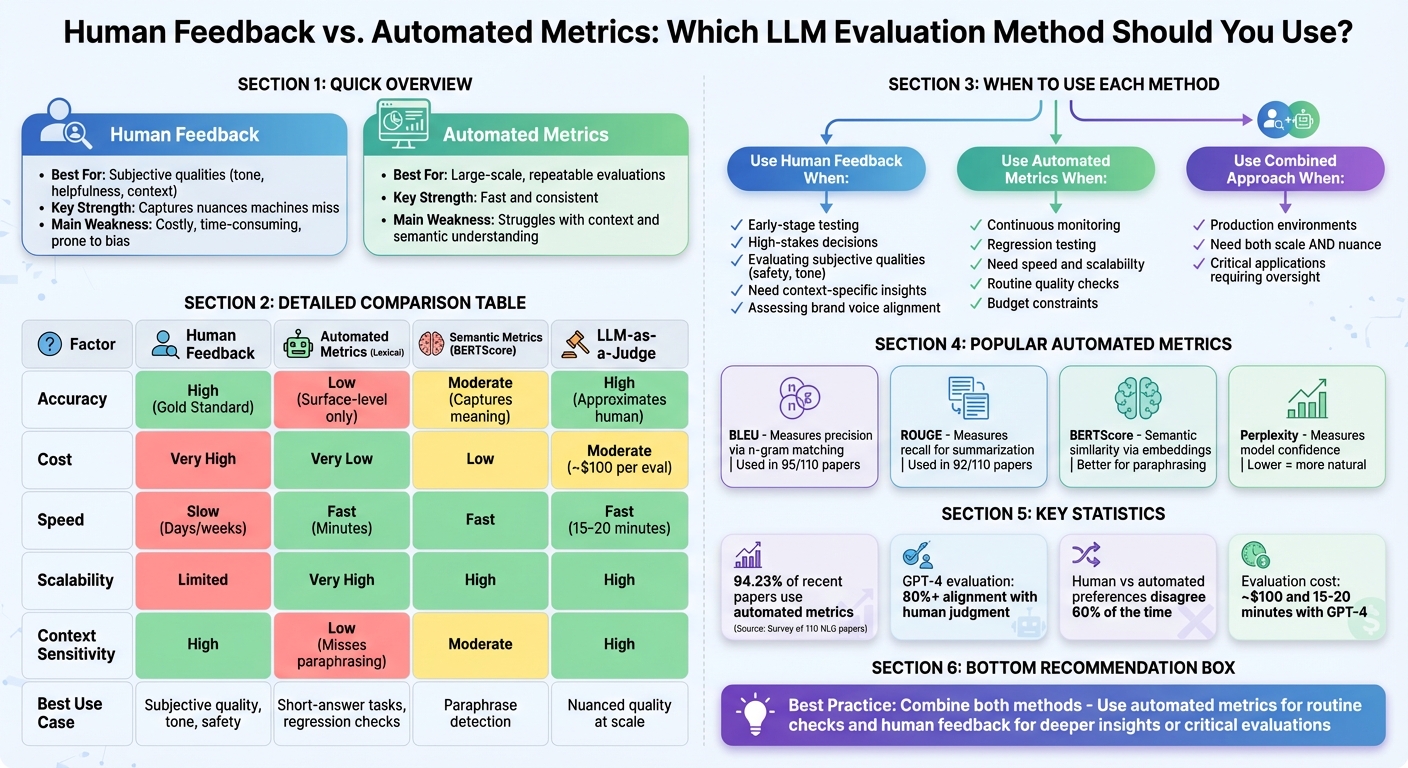
When evaluating large language models (LLMs), two main approaches exist: human feedback and automated metrics. Each has its strengths and weaknesses, and the choice depends on your goals, timeline, and resources. Here's a quick breakdown:
- Human Feedback: Best for assessing subjective qualities like tone, helpfulness, and user context. It captures nuances machines often miss but is costly, time-consuming, and prone to human bias.
- Automated Metrics: Efficient for large-scale, repeatable evaluations. Metrics like BLEU, ROUGE, and BERTScore are fast and consistent but struggle with context and semantic understanding.
Key Takeaways:
- When to Use Human Feedback: Early-stage testing, high-stakes decisions, or evaluating subjective qualities like safety and tone.
- When to Use Automated Metrics: Continuous monitoring, regression testing, or tasks requiring speed and scalability.
Quick Comparison:
| Factor | Human Feedback | Automated Metrics |
|---|---|---|
| Accuracy | High for nuance | Moderate to high |
| Cost | Expensive | Affordable |
| Speed | Slow (days/weeks) | Fast (minutes) |
| Scalability | Limited | High |
| Context Sensitivity | High | Moderate |
Combining both methods often yields the best results. Use automated metrics for routine checks and human feedback for deeper insights or critical evaluations.
Human Feedback vs Automated Metrics: Complete Comparison Guide for LLM Evaluation
What Are Automated Metrics?
Automated metrics are essentially algorithms designed to evaluate the quality of text produced by large language models (LLMs). Think of them as a performance report, providing scores that assess how well an LLM performs.
These metrics can be divided into two main types: reference-based and reference-free. Reference-based metrics compare the generated content to a predefined "ground truth", while reference-free metrics focus on the internal qualities of the text, like its fluency or logical structure.
The appeal of automated metrics lies in their efficiency. As Kishore Papineni explained:
"Human evaluations of machine translation are extensive but expensive. Human evaluations can take months to finish and involve human labor that can not be reused. We propose a method of automatic machine translation evaluation that is quick, inexpensive, and language-independent".
Their popularity is undeniable. In a survey of 110 recent papers on natural language generation, 94.23% relied on automated metrics for evaluation. These tools have become essential for testing LLMs, especially when frequent evaluations are needed on a large scale.
Common Automated Metrics: BLEU, ROUGE, BERTScore, and Perplexity
Several automated metrics dominate the field, each serving specific purposes:
- BLEU (Bilingual Evaluation Understudy): This metric measures precision by checking how many word sequences (n-grams) in the generated text match the reference text. Originally developed for machine translation, it remains widely used - appearing in 95 out of 110 papers in one study.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE flips the focus to recall, assessing how much of the reference text is captured in the generated output. It's particularly favored for summarization tasks, appearing in 92 of the 110 papers. While BLEU asks, "How much of what you said was correct?", ROUGE asks, "Did you include all the important parts?"
- BERTScore: A newer metric that uses contextual embeddings from BERT to evaluate semantic similarity. This allows it to capture meaning even when different words are used, making it better at handling nuances like paraphrasing.
- Perplexity: This metric measures how confident the model is in its predictions. A lower perplexity score indicates the model found the text more predictable and natural. It's often used to gauge fluency and how well the model understands language patterns.
Other domain-specific metrics, such as pass@k (for code testing) and Faithfulness (for factual consistency), cater to specialized evaluation needs.
Advantages of Automated Metrics
The biggest strengths of automated metrics are their speed and scalability. For instance, running a full evaluation suite with GPT-4 as the evaluator costs about $100 and takes just 15–20 minutes - far faster than coordinating human reviewers. This makes them ideal for continuous testing, where every model update or code change needs quick feedback.
Another key benefit is consistency. Unlike human evaluators, automated metrics don't experience fatigue or mood swings. The same input will always yield the same score, making it easier to track progress over time and identify regressions.
Additionally, these metrics are standardized and reproducible. A BLEU score, for example, can be replicated by other researchers using the same method. This has made automated metrics the backbone of widely used benchmarks like MMLU and GSM8K, which evaluate and compare model capabilities across various tasks.
Drawbacks of Automated Metrics
Despite their utility, automated metrics often fall short in capturing what truly matters. Metrics like BLEU and ROUGE rely heavily on word overlap, which can lead to misleading results. As researcher Thibault Sellam pointed out:
"Text generation has made significant advances in the last few years. Yet, evaluation metrics have lagged behind, as the most popular choices (e.g., BLEU and ROUGE) may correlate poorly with human judgment".
One major issue is semantic nuance. A model might produce an accurate paraphrase but score poorly on BLEU simply because it used different words. On the flip side, it could score well by copying the reference text verbatim, even if it misses the intended meaning entirely.
Even newer metrics based on LLMs have limitations. For instance, research on DeepSeek-R1-32B revealed that over 90% of its judgments contained unexplained variance, meaning its final scores often didn't align with its own evaluation criteria. These tools also suffer from "factor collapse", where scores for different aspects like style and correctness end up being nearly identical, with correlations exceeding 0.93.
There's also a reproducibility problem. Many studies fail to provide implementation details, making it difficult to verify results. For example, 63.6% of papers using BLEU and 62.6% using ROUGE lacked sufficient information on how the metrics were applied. This lack of transparency undermines the reliability of the findings.
What Is Human Feedback?
Human feedback involves real people evaluating outputs from large language models (LLMs) based on practical, real-world criteria. Unlike automated metrics that rely on word matching, human evaluators focus on whether a response solves a problem, feels natural, or fits the intended context.
As Tom Hosking, a researcher in LLM evaluation, puts it:
"Human feedback has become the de facto standard for evaluating the performance of Large Language Models, and is increasingly being used as a training objective".
Why? Because humans can assess qualities that algorithms can’t easily measure. For instance, they can judge whether a chatbot's tone is professional, decide if an answer is genuinely helpful rather than just technically correct, and determine if a response properly addresses the user’s needs.
Human feedback also captures context-specific subtleties that automated systems often miss. For example, a model might produce a technically accurate but overly long response - what’s called "verbosity bias". While automated metrics like ROUGE might reward this due to word overlap, a human evaluator would recognize it as unhelpful. Similarly, humans can identify subtle safety issues, such as insensitive language or attempts to bypass content filters, that keyword-based systems might overlook.
The challenge is gathering this feedback systematically. By April 9, 2025, platforms like Chatbot Arena had collected over 2.8 million human-labeled cases to evaluate 223 different LLMs. This demonstrates both the scale and importance of human evaluation.
How to Collect Human Feedback
Several methods exist to gather human evaluations systematically:
- Pairwise comparison: Evaluators compare two responses - Response A and Response B - and choose the better one or mark them as tied. This method is straightforward but becomes time-intensive as the number of models grows.
- Pointwise evaluation: Evaluators rate a single response on a scale (e.g., 1 to 5). This approach scales more efficiently and allows for faster iteration. A study of 15 machine learning practitioners found pointwise methods enabled more task-specific adjustments and easier judgments.
- Multi-label "response set" ratings: Evaluators assign multiple valid ratings to a response, accommodating situations with more than one acceptable answer.
- Interactive evaluation frameworks: Tools like HALIE assess entire human-LLM interactions. Developed by the Stanford Center for Research on Foundation Models, HALIE evaluated four advanced models (including GPT-3 variants) across five tasks, measuring subjective experiences like enjoyment and ownership. This revealed that static benchmarks don’t always predict real-world performance.
Interestingly, preferences inferred from different methods (ratings vs. rankings) disagree 60% of the time, highlighting how the choice of evaluation method impacts results.
Advantages of Human Feedback
Human feedback shines in assessing qualities that matter to users. Andrea Polonioli from Coveo explains:
"Accuracy does not speak with one voice - and understanding how models perform is central to grasping their capabilities and limitations".
Humans excel at evaluating aspects that lack clear definitions, such as whether a response is helpful (addressing the user’s intent) or comprehensive (covering all parts of a question). They can also judge tone and style, like whether a customer service reply sounds professional or a creative response captures the right mood. Moreover, humans can identify when a model provides the correct answer for the wrong reasons, exposing flaws in logical reasoning that automated metrics might miss.
Human feedback also offers real-world relevance, showing how well a system performs in the specific context it’s designed for rather than just excelling on abstract tests. In specialized fields like healthcare, finance, or law, domain experts provide critical insights into technical accuracy that general evaluators or automated tools might overlook.
Additionally, human evaluators can adapt their criteria during assessments, catching issues like subtle toxicity, bias, or attempts to manipulate the system that automated filters might miss.
Drawbacks of Human Feedback
Despite its strengths, human feedback has limitations, especially when it comes to scalability. Coordinating human evaluators is more time-consuming and expensive than automated evaluations.
Inconsistency is another challenge. Human evaluators bring personal biases, and research shows they are prone to "assertiveness bias", where a model’s confident tone can skew perceptions of its accuracy. This means a response that sounds certain might be rated as correct, even if it isn’t.
Ensuring agreement among evaluators is also tough. For reliable evaluations, a Cohen’s kappa score above 0.60 is typically the goal, requiring clear guidelines and thorough training.
Position bias is another issue. Evaluators may unconsciously favor the first or last response in a comparison, rather than judging purely on merit. To counter this, experimental designs often randomize response order.
Finally, human feedback doesn’t eliminate subjectivity. As Jeffrey Ip, cofounder of Confident AI, notes:
"The secret to making a good LLM evaluation metric great is to make it align with human expectations as much as possible".
But human expectations vary widely, especially for subjective qualities like creativity or persuasiveness.
Human Feedback vs. Automated Metrics: Direct Comparison
After looking at human feedback and automated metrics separately, it’s time to see how they stack up against each other.
When evaluating your language model, you’ll need to juggle multiple factors: cost, speed, accuracy, and sensitivity to context. Each method has its strengths, depending on the situation.
Human feedback is unmatched when it comes to capturing nuance and understanding context. But there’s a catch - it’s expensive and time-consuming. As Ehsan Doostmohammadi from Linköping University puts it:
"Human evaluation is the gold standard of assessment in natural language processing, but is not widely used in the literature due to its high costs".
On the other hand, automated evaluations are significantly faster and cheaper. For instance, using GPT-4 for evaluation costs around $100 and takes just 15–20 minutes. Compare that to human evaluations, which can stretch out over days or even weeks. This makes automation a go-to choice for tasks like real-time monitoring or regression testing during development cycles.
Different automated metrics also have their own quirks. Lexical metrics like ROUGE-L work well for short-answer tasks because they focus on word overlap, but they fall short when dealing with free-form text. Semantic metrics, such as BERTScore, are better at capturing meaning beyond exact matches. Then there’s the LLM-as-a-judge approach, which has shown remarkable results - GPT-4’s evaluations align with human judgments more than 80% of the time, rivaling even human-to-human agreement levels.
That said, context matters. For example, when GPT-4 doesn’t have reference answers to rely on, its alignment with human ratings drops significantly - from 0.81 to 0.62 in English tasks. This highlights a key limitation: automated methods struggle with subjective aspects like tone or creativity.
Here’s a quick snapshot of how these methods compare:
| Factor | Human Feedback | Automated Metrics (Lexical) | Semantic Metrics (BERTScore) | LLM-as-a-Judge |
|---|---|---|---|---|
| Accuracy | High (Gold Standard) | Low (Surface-level only) | Moderate (Captures meaning) | High (Approximates human) |
| Cost | Very High | Very Low | Low | Moderate (~$100 per eval) |
| Scalability | Low (Days/weeks) | Very High (Minutes) | High | High (15–20 minutes) |
| Reliability | Subjective/Biased | High (for short text) | Moderate | Context-dependent |
| Context Sensitivity | High | Low (Misses paraphrasing) | Moderate | High |
| Best Use Case | Subjective quality, tone, safety | Short-answer tasks, regression checks | Paraphrase detection | Nuanced quality at scale |
This comparison makes it clear: the right choice depends heavily on your specific needs. While human feedback is ideal for evaluating subjective qualities, automated metrics shine when speed and scalability are priorities.
Combining Human Feedback with Automated Metrics
Blending automated metrics with human feedback creates a balanced approach to evaluation, particularly in dynamic production environments. Automated systems handle scale and efficiency, while human input adds depth, addressing nuances like tone, brand voice, and subtle quality indicators that machines often miss.
This hybrid strategy is already delivering results. For instance, DoorDash uses a RAG-based support chatbot evaluated on five key metrics: retrieval correctness, response accuracy, grammar, coherence, and relevance. An LLM-as-a-judge system scales the evaluation process, while human reviewers analyze random transcript samples. This dual approach ensures the automated judge remains calibrated and catches issues it might overlook. As Greg Brockman, Co-founder of OpenAI, aptly notes:
"Evals are surprisingly often all you need".
Examples of Combined Approaches
Several methods illustrate how human feedback and automation can work together effectively:
-
LLM-as-a-judge systems: These systems can approximate human judgment at scale when paired with proper oversight. Nathan Lambert from the Allen Institute for AI highlights the importance of RLHF (Reinforcement Learning with Human Feedback), stating:
"RLHF is what takes these answers and crafts them into the reliable, warm, and engaging answers we now expect from language models".
- Decomposing quality into unit tests: Breaking down evaluation into specific, testable criteria - like factual accuracy, coherence, and safety - simplifies the process. Research shows that using a multidimensional rubric with nine targeted questions (e.g., naturalness, conciseness) enabled an automated system to predict human satisfaction with an RMS error of less than 0.5, doubling the accuracy of uncalibrated baselines.
- Multi-label rating systems: These systems address situations where multiple answers can be correct. Unlike forced-choice ratings, multi-label "response set" ratings allow raters to identify all plausible interpretations. This approach has been shown to improve automated judge performance by up to 31%.
At GitHub, evaluation methods vary by product. For Copilot's code completions, automated metrics assess the percentage of passed unit tests across 100 containerized repositories. Meanwhile, for Copilot Chat, an LLM judge evaluates complex queries, with regular calibration to maintain alignment.
How to Implement Combined Approaches in Production
To adopt this combined approach effectively, start by defining specific evaluation criteria, such as retrieval correctness, response accuracy, grammar, coherence, and relevance.
- Set up a tiered validation strategy: Asana engineers use an in-house LLM unit testing framework for rapid iteration, employing a best-of-3 LLM-as-a-judge method to verify assertions. Product managers manually review realistic data in sandbox environments to catch subtle issues before production.
- Regularly recalibrate automated judges: At Webflow, automated LLM judge scores are supplemented with weekly manual scoring to detect unexpected regressions.
- Anchor evaluations with human responses: Providing human-written "gold standard" responses as context can improve agreement with automated judges by up to 3.2%.
- Develop a tailored prompt library: GitLab conducts daily re-validation against its prompt library and manually examines results to spot trends and domain-specific issues. Generic benchmarks often fail to address the unique challenges of specific applications.
For critical evaluations, consider a best-of-N approach (e.g., best-of-3) to ensure consistent and accurate signals. Tools like Latitude can simplify this process by offering integrated solutions for monitoring model behavior, collecting structured human feedback, running evaluations, and refining LLM-driven features.
Since evaluation criteria evolve, keeping human reviewers involved in refining both the criteria and automated systems is essential for maintaining a reliable and adaptable assessment process.
When to Use Each Evaluation Method
Deciding between human feedback and automated metrics depends on where you are in development, your risk tolerance, and your evaluation goals. Early on, it's best to rely on human evaluations to confirm if your model is even viable. This prevents wasting time and resources on solutions that may not pan out.
Once you've established that the model works at a basic level, automated metrics become your go-to for constant monitoring. They help you quickly spot regressions. Meanwhile, human evaluation steps in for more critical moments - like high-stakes decisions or when you're deciding whether the model is ready to launch. The process can look like this: run automated metrics with every model update to catch performance dips, then bring in human reviewers if results fall below certain benchmarks or involve sensitive user groups. This approach smoothly transitions your evaluation process from prototyping to deployment.
Resource limitations also play a role in your evaluation strategy. Sometimes, a model that's faster but slightly less accurate is better suited for production. Jeffrey Ip highlights the risk of overloading on metrics, saying, "Too many metrics dilute focus". He suggests sticking to his "5 Metric Rule": use 1–2 custom metrics for specific goals and 2–3 general metrics to track overall system performance.
For day-to-day production monitoring, automated metrics are ideal for their speed and scalability. But periodic human evaluations are still essential - they help fine-tune rubrics and catch nuanced failures that automated systems might overlook. This hybrid approach ensures comprehensive oversight without overburdening the evaluation process. It's also worth noting that human preference scores can sometimes be biased. Studies show that the "assertiveness" of a language model's output can influence how factual errors are perceived. This makes it crucial to investigate when human and automated evaluations don't align.
Tools like Latitude simplify this hybrid evaluation process. They combine model observation, structured human feedback, and evaluation tracking into one platform. This eliminates the need to build custom infrastructure, making it easier to manage both automated and human evaluations efficiently.
Conclusion
Creating dependable LLM-powered products relies on combining human feedback with automated metrics to achieve the right mix of speed, consistency, nuance, and judgment. Automated metrics are crucial for ensuring quick and repeatable monitoring, helping to catch regressions during every model update. Meanwhile, human evaluation brings a deeper understanding of subjective elements like tone, helpfulness, and alignment with policies.
The most effective approach treats these two methods as complementary tools rather than competing ones. Automated metrics handle the day-to-day monitoring, while human evaluations are reserved for critical tasks like high-stakes decisions, safety-sensitive scenarios, and periodic quality assessments. This layered strategy ensures both efficiency and accuracy.
When automated metrics and human evaluations conflict, it’s a signal to dig deeper. These disagreements often highlight gaps in the metrics or reveal new failure modes. For example, research shows that human evaluators and LLM systems can disagree on 18% of system pairs, with automated scores sometimes hitting 0.95 while human-verified scores fall between 0.68 and 0.72. Such findings highlight the importance of balancing both methods.
To streamline evaluations, adopt a mix of human insight and automated tools. A helpful guideline is the "5 Metric Rule", which uses 1–2 custom metrics alongside 2–3 generic ones for balanced assessments. Platforms like Latitude offer an all-in-one solution, combining model monitoring, human feedback, and evaluation tracking - eliminating the need for custom-built infrastructure.
FAQs
How do human feedback and automated metrics work together to evaluate language models?
Human feedback and automated metrics work together to cover different facets of evaluating language models. Automated metrics excel at quickly and consistently analyzing large datasets, particularly for tasks with clear, objective benchmarks like classification or ranking. They’re great for monitoring progress over time and spotting measurable changes in performance.
On the other hand, human feedback captures the finer details that automated tools often miss - things like context, relevance, and safety. This makes it invaluable for assessing subjective or nuanced qualities, ensuring models meet user expectations and fit real-world applications. By blending these two approaches, you can create a more well-rounded evaluation process that combines efficiency with a deeper understanding of the model’s capabilities.
What are the drawbacks of using only automated metrics to evaluate LLMs?
Automated metrics offer a quick and budget-friendly way to evaluate the performance of large language models (LLMs). However, they have their shortcomings. These tools often fall short when it comes to judging more nuanced aspects like factual accuracy, coherence, and relevance - qualities that are essential for gauging how well a model truly performs. For example, while metrics like ROUGE or BLEU are suitable for structured tasks, they tend to be less dependable when evaluating free-flowing or creative outputs.
Another challenge is that automated methods can sometimes yield misleading results, especially when they lack the ability to replicate human judgment or understand context. Even advanced systems like GPT-4, which have demonstrated potential in ranking outputs similarly to human evaluators, can struggle with tasks that require deeper contextual awareness or an understanding of subtle language nuances. To get a more comprehensive evaluation, it's crucial to pair automated metrics with human feedback, which can capture the finer details that algorithms often overlook.
When should you prioritize human feedback over automated metrics in evaluating LLMs?
Human feedback shines brightest when evaluating subjective, nuanced, or context-dependent aspects of a large language model's (LLM) performance. For example, judging factors like relevance, helpfulness, safety, or conversational quality often requires the kind of insight and understanding that only humans can bring to the table. These areas are tricky for automated metrics to assess because they depend heavily on subtle context and individual user expectations.
On the flip side, automated metrics excel at tasks with clear, objective criteria, such as classification or structured predictions. But when the focus shifts to ensuring outputs meet real-world user needs or adhere to complex quality standards, human feedback becomes indispensable. It provides a deeper evaluation of safety, appropriateness, and overall user satisfaction - elements that automated tools may miss or misinterpret.
