
How to Identify and Reduce Dataset Bias in LLMs
Only systematic detection, counterfactual augmentation, adversarial debiasing, and continuous monitoring can meaningfully reduce dataset bias in language models.

Bias in large language models (LLMs) is a major challenge. It arises from imbalances in training data, leading to unfair outputs that can reinforce stereotypes or cause harm in areas like healthcare, hiring, and education. This guide explains how to detect and address dataset bias to build more reliable AI systems.
Key Takeaways:
- What is dataset bias? Imbalances in training data that lead to unfair or inaccurate model behavior. Examples include under-representation of certain groups or biased labeling.
- Why it matters: Bias can result in representational harms (reinforcing stereotypes) and allocational harms (unequal resource distribution).
- How to fix it: Use tools like CrowS-Pairs and BEATS to detect bias, apply techniques like Counterfactual Data Augmentation and Adversarial Debiasing to reduce it, and monitor outputs regularly.
Steps to Address Bias:
- Detect Bias: Analyze data distributions and model performance across demographic groups. Use frameworks like HolisticBias or tools like BiasLens to measure disparities.
- Reduce Bias: Balance datasets with counterfactual examples, train adversarial models to de-emphasize sensitive attributes, and refine outputs with preprocessing and postprocessing techniques. Developers can also mitigate bias through advanced prompt engineering to guide model behavior.
- Monitor Continuously: Track metrics like toxicity and stereotype scores over time. Combine automated tools with expert feedback to identify and address emerging issues.
By focusing on high-quality data and regular evaluations, you can minimize bias and improve the trustworthiness of your LLMs.
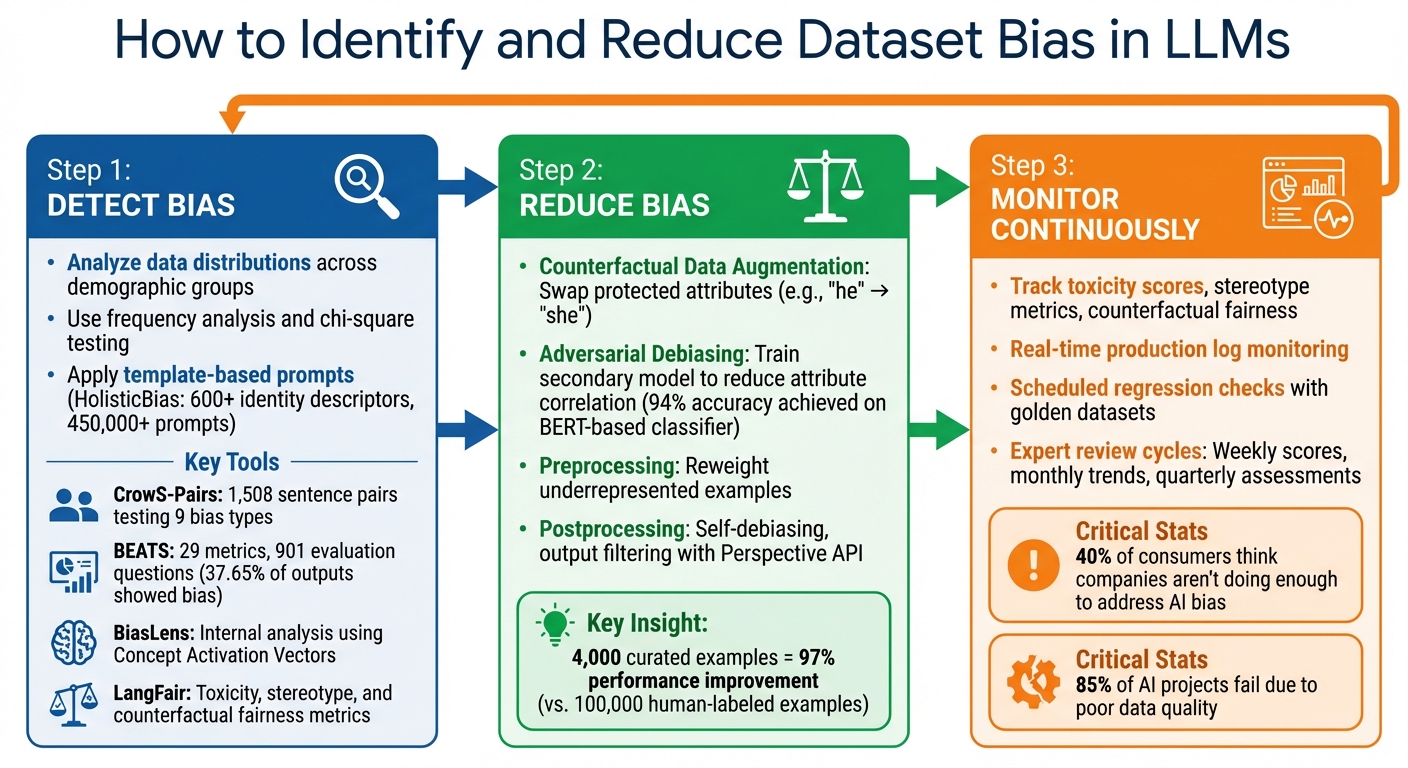
3-Step Framework to Detect and Reduce Bias in Large Language Models
Step 1: Detecting Bias in Datasets
Before trying to address bias in your training data, the first step is to identify it. This involves a combination of manual inspection and automated tools to systematically analyze the dataset.
Analyzing Data Distribution
Begin by assessing how well your data represents different groups. Look for signs like missing or unrealistic feature values, which could indicate under-representation or collection errors. Also, check for data imbalances where some groups are over- or under-represented compared to their actual prevalence in the real world.
To dig deeper, evaluate model performance across subgroups such as age, gender, or ethnicity. Use methods like frequency analysis and chi-square testing to uncover statistically significant disparities. For example, if you're working with medical data, don’t just evaluate the model's overall accuracy - analyze how it performs for different age groups, genders, and ethnicities.
"Misrepresentation [is] an incomplete or non-representative distribution of the sample population generalized to a social group." – Isabel O. Gallegos et al., Stanford University
A practical way to probe for bias in your dataset is through template-based prompts. The HolisticBias framework, for instance, includes nearly 600 identity descriptors spanning 13 demographic dimensions, resulting in over 450,000 unique prompts for auditing bias. This method helps you identify whether certain demographic groups are frequently associated with negative or offensive outputs.
Once you’ve identified imbalances, use benchmark tools to measure bias more precisely.
Using Benchmark Tools to Evaluate Bias
One way to evaluate bias is by using CrowS-Pairs, a dataset of 1,508 sentence pairs that tests for nine types of social biases, including those related to disability, physical appearance, and socioeconomic status. It measures whether models favor stereotypical over anti-stereotypical sentences, though some studies have raised concerns about noise and reliability in its results .
Here are some tools to consider:
| Tool | Focus Area | Key Metrics |
|---|---|---|
| BEATS | Multi-dimensional bias across 29 metrics | Uses "LLM-as-a-Judge" to evaluate model outputs |
| LangFair | Assessment tailored to specific use cases | Measures toxicity probability, stereotype fraction, and counterfactual fairness |
| BiasLens | Internal model analysis | Leverages Concept Activation Vectors (CAVs) without requiring labeled data |
The BEATS framework is particularly insightful. Tests using its 901 curated evaluation questions revealed that 37.65% of outputs from leading models exhibited some form of bias. Tools like the Hugging Face evaluate library also provide practical metrics. For instance, toxicity measures the likelihood of hate speech, regard evaluates language polarity toward different groups, and HONEST assesses gendered stereotypes. These metrics use raw scores between 0.0 and 1.0, making it easier to compare outputs across different models.
"A simple difference in pronoun can result in a higher toxicity ratio for female model completions versus male ones." – Sasha Luccioni, Research Scientist, Hugging Face
It’s important to keep in mind that fairness through unawareness doesn’t work with large language models (LLMs). Sensitive attributes are deeply embedded in the natural language data used for training, which makes systematic detection of bias absolutely essential.
Step 2: Reducing Dataset Bias
After spotting bias in your dataset, the next move is to tackle it head-on. This involves using strategies at various stages - before training, during training, and after generating outputs. By combining these methods, you can achieve better outcomes. These approaches work hand in hand with the detection techniques mentioned earlier to help create more equitable model results.
Counterfactual Data Augmentation
Counterfactual Data Augmentation (CDA) helps balance your dataset by swapping out protected attributes in the data. For instance, you might replace "he" with "she" in sentences about doctors or change "John" to "Aisha" in professional scenarios. This helps the model move away from stereotypical patterns, like associating "engineer" mostly with men or "nurse" primarily with women .
To implement CDA, identify protected attributes (like gender, race, or religion) and use automated scripts to create counterfactual pairs. These pairs are then added to your dataset for fine-tuning. This method is especially effective in addressing representational harms, such as stereotyping or excluding certain groups when dominant groups are overly represented in training data .
Adversarial Debiasing
Adversarial debiasing introduces a secondary model, called an adversary, during training. This adversary tries to predict protected attributes (like gender or ethnicity) from the main model’s hidden layers or outputs. To counter this, the main model’s loss function is adjusted to penalize the adversary’s success, making the model’s internal representations less tied to these attributes .
In August 2023, researchers from UC Berkeley - He Shi, Joe Damisch, and Forrest Kim - applied this technique to Meta's Llama 2 model to reduce racial and professional stereotypes. They used a bias classifier based on BERT, trained on StereoSet, which achieved 94% accuracy. This generated fine-tuning data that lowered bias scores in specific areas, though it did slightly impact performance on general question-answering tasks.
Preprocessing and Postprocessing Techniques
Beyond CDA and adversarial debiasing, preprocessing and postprocessing methods can further improve model fairness. Preprocessing focuses on the data before training. For example, reweighting assigns more importance to underrepresented examples, such as those showing women in STEM roles . Other techniques include filtering out biased content or anonymizing sensitive attributes in training data to reduce harmful associations.
Postprocessing, on the other hand, refines outputs after they’re generated. Self-debiasing adjusts token probabilities during text generation to reduce biased language. Tools like the Perspective API can flag or block harmful outputs before they reach users. Additionally, user feedback mechanisms allow biased responses to be reported and used as negative examples in future reinforcement learning sessions .
"For a given problem, you can choose any one of N model architectures off the shelf, but your ultimate performance is going to come from the data you marry with that model architecture."
– Jason Corso, Professor of Robotics and Co-Founder/CSO of Voxel51
One example highlights the power of high-quality datasets: a curated dataset of just 4,000 examples outperformed a planned dataset of 100,000 human-labeled examples, improving model performance by 97% while using only 4% of the original data volume. This underscores the importance of expert curation over sheer volume when addressing bias.
Step 3: Monitoring and Improving Bias Reduction
Reducing bias isn’t a one-and-done task - it requires constant vigilance. As new data flows into production, continuous monitoring helps ensure that previously addressed biases don’t sneak back in, while also catching new patterns as they emerge.
A telling statistic: 40% of consumers think companies using generative AI aren’t doing enough to address bias and misinformation. Meanwhile, Gartner reports that as many as 85% of AI projects fail, often due to poor data quality. By establishing robust monitoring workflows now, you can avoid costly setbacks later. This highlights the importance of structured, ongoing evaluation methods, which we’ll explore in detail.
Tracking Bias Metrics Over Time
Once you've implemented techniques like counterfactual data augmentation or adversarial debiasing, the next step is consistent monitoring to identify any new or re-emerging biases. This involves both real-time tracking and scheduled regression checks. Real-time monitoring of production logs can help flag problematic outputs as they occur, while periodic "Batch Mode" testing against a curated "golden dataset" ensures your model performs well on challenging edge cases. Bias metrics should be calculated at the use-case level, not just for the overall model.
Key metrics to track include:
- Toxicity scores: Metrics like Expected Maximum Toxicity and Toxicity Probability.
- Stereotype metrics: For example, the Co-occurrence Bias Score.
- Counterfactual fairness tests: Run identical prompts with only protected attributes changed (e.g., swapping "he" for "she") and compare the outputs.
Set a regular cadence for evaluations: calculate bias scores weekly, review trends monthly, and conduct in-depth assessments quarterly. Tools like Latitude simplify this process by offering observability workflows that track aggregated statistics, score distributions, and trends over time. They even provide "Live Evaluation" features to automatically test new production data for safety concerns.
Collecting Feedback from Domain Experts
While automated monitoring is invaluable for scale, domain experts play a critical role in spotting subtle, context-specific biases that algorithms might overlook. A robust review process should combine both approaches. Start with data scientists identifying statistical patterns, followed by domain experts analyzing contextual relevance, and conclude with an ethics committee evaluating broader societal impacts.
"The success of any ML/AI project hinges on the effective continuous refinement of both the data and the model." – Jason Corso, Co-Founder and Chief Science Officer of Voxel51
To make this process efficient, create structured feedback loops. Production data can be sent back to experts for annotation, which then updates evaluation datasets. Collaborative environments where engineers and subject matter experts can design and test prompts together are particularly effective for catching nuanced biases early. To scale expert involvement without overwhelming your team, break large curation tasks into smaller, manageable steps.
Conclusion: Building Fairer LLMs with Better Data Practices
Creating fairer large language models (LLMs) starts with adopting structured practices to identify, minimize, and continuously monitor bias. The three-step process outlined - using distribution analysis and benchmarking to detect bias, applying methods like counterfactual data augmentation to address it, and maintaining ongoing monitoring with expert input - lays the groundwork for responsible AI development.
Studies show that bias is a persistent issue in a large portion of model outputs, and many AI projects stumble due to poor data quality. But there’s good news: research highlights that even a small, high-quality dataset - just 4,000 carefully curated examples - can enhance model performance by an impressive 97%. This underscores a crucial point: when it comes to training data, quality trumps quantity.
To make meaningful progress, collaboration between engineers and domain experts is key. While technical teams excel at uncovering statistical patterns, they often overlook the nuanced cultural and contextual biases that experts can spot with ease. Platforms like Latitude help bridge this gap by offering shared spaces where teams can design prompts, evaluate outputs, and track bias metrics together in real time. This approach aligns with research showing that 40% of consumers feel companies aren’t doing enough to address AI bias.
To get started, focus on tracking a single bias metric, schedule monthly expert reviews, and integrate structured regression tests into your workflow. Over time, these practices evolve from being reactive measures into a proactive system - one that not only reduces bias but also builds user trust and enhances model performance with every iteration.
FAQs
What are the best tools to detect and address bias in datasets for LLMs?
Detecting and addressing bias in datasets for large language models (LLMs) can be simplified with a variety of specialized tools. AI Fairness 360 (AIF360), a Python library, offers more than 70 metrics to uncover bias and provides algorithms to adjust data, promoting fairer outcomes. 🤗 Evaluate by Hugging Face is another handy resource, featuring pre-built bias tests that evaluate model predictions across diverse demographic groups - perfect for integrating into existing workflows. Additionally, LangFair focuses on fairness evaluations directly from LLM outputs, giving engineers a way to measure bias in specific scenarios.
For a more comprehensive approach, the BEATS toolkit includes 29 metrics that assess aspects like bias, ethics, and factual accuracy. The AWS bias-mitigation-for-LLMs repository also offers practical examples of debiasing methods, such as counterfactual augmentation. On the Latitude platform, these tools come together in a collaborative setting, enabling teams to uncover hidden biases, measure their effects, and implement solutions efficiently. Using these resources can help create fairer and more trustworthy LLMs.
What is Counterfactual Data Augmentation, and how does it help reduce bias?
Counterfactual Data Augmentation tackles bias by adding altered examples to the dataset. These examples systematically change key attributes like gender, race, or age. By doing so, the model is trained to disregard these attributes, ensuring it doesn't develop biased or stereotypical associations from the original data.
This method helps the model shift its focus to the actual content instead of sensitive attributes, promoting fairer and more balanced outcomes.
Why is it important to continuously monitor for bias in LLMs?
Continuous monitoring plays a key role in identifying biases that can develop or reappear as data and user interactions change over time. By regularly reviewing model outputs, you can spot and address problems early, helping to maintain balanced and fair results.
Staying vigilant not only ensures your model remains reliable but also strengthens user trust by consistently providing impartial and dependable outcomes.
