
Real-Time Feedback Techniques for LLM Optimization
Explore how real-time feedback enhances large language models, enabling continuous improvement and addressing challenges in optimization.

Real-time feedback is revolutionizing how large language models (LLMs) improve performance. Unlike traditional methods that rely on static datasets, this approach allows LLMs to adjust dynamically during live interactions. Here's what you need to know:
- What It Is: Real-time feedback lets LLMs refine outputs based on user input and performance signals during use.
- Why It Matters: It addresses limitations of static fine-tuning by enabling continuous improvement, making models more effective for specific tasks.
- Key Challenges: High computational costs, managing data, and ensuring system accuracy are common obstacles.
- Core Methods: Feedback systems collect explicit (user ratings) and implicit (session duration) inputs, process them, and apply updates via closed-loop workflows.
- Evaluation Tools: A/B testing, prompt engineering, and metrics like accuracy and latency help validate improvements.
Core Methods for Real-Time Feedback Integration
Creating effective real-time feedback systems involves a well-thought-out approach to collecting, processing, and applying user input. The techniques discussed here transform feedback into ongoing improvements for large language models (LLMs).
Feedback Collection Systems
At the heart of any feedback-driven process lies the ability to gather input from a variety of sources. A good system captures both explicit feedback - like user ratings or correction suggestions - and implicit signals, such as session duration or task completion rates. LLMs gather input not just from users, but also from domain experts and automated evaluation systems to assess performance comprehensively.
Natural language feedback is especially useful for understanding user intent and satisfaction. Domain experts contribute deeper insights, catching subtle errors or compliance concerns that automated tools might overlook.
Automated evaluation systems play a complementary role by offering consistent and scalable assessments of model outputs. Metrics such as accuracy, precision, recall, latency, and throughput help monitor performance and identify potential issues before they affect users.
Processing Natural Language Feedback
Once feedback is collected, it needs to be processed efficiently to drive timely improvements. This often involves converting unstructured feedback into actionable insights. LLMs can analyze and categorize this input, creating a self-optimizing system where AI refines AI.
One effective method is training reward models using natural language feedback. This approach, called Reinforcement Learning from AI Feedback (RLAIF), uses signals generated by LLMs themselves to guide fine-tuning. By focusing on specific human preferences - such as clarity, relevance, or tone - LLMs can process feedback in a more nuanced way.
For instance, Anthropic's 2023 Helpfulness/Harmlessness dataset has been used to fine-tune models through RLAIF. The key is selecting reward models that align the LLM with desired traits like helpfulness, honesty, and harmlessness.
Closed-Loop Optimization Workflows
After feedback is processed, it needs to be translated into meaningful updates through automated workflows. Closed-loop systems take these insights and implement targeted improvements. These workflows must be scalable, automated, and transparent to ensure consistent optimization without overburdening human teams.
A well-designed system channels different types of feedback to the right areas. For example, complaints about factual inaccuracies might trigger fact-checking workflows, while feedback on tone could lead to adjustments in prompt engineering. Prioritization is critical - feedback should be ranked by factors like frequency, severity, and overall impact.
Optimization efforts should also include experimental frameworks, such as A/B testing, to compare results before and after updates. Tracking performance metrics over time provides a clearer picture of the model's progress. Additionally, feedback loops should capture both immediate reactions and long-term satisfaction to fully understand user experience.
Collaboration with domain experts is another essential aspect, especially for addressing complex compliance issues. Experts can help translate these challenges into specific, actionable tasks that LLMs can handle effectively.
To streamline these processes, platforms like Latitude offer tools for managing intricate feedback loops. Latitude’s open-source framework fosters collaboration between engineers and domain experts, making it easier to build and maintain advanced LLM features.
Ultimately, efficient workflows strike a balance between improving performance and managing resource costs, ensuring that the benefits of real-time feedback justify the investment in infrastructure and effort.
Testing and Evaluation in Feedback-Driven LLM Optimization
After collecting and processing feedback, thorough testing is essential to ensure that real-time adjustments translate into measurable performance improvements. Below, we’ll explore specific testing methods and metrics that help assess and refine these optimizations.
A/B Testing and Iterative Experiments
A/B testing remains a go-to method for evaluating the impact of feedback-driven changes in live environments. This approach compares a control group to a variant group, isolating one variable at a time to measure its effect. The key is to design experiments that focus on a single change and ensure the sample size is large enough for reliable results.
For instance, a chatbot team tested whether a reward model optimized for user engagement could enhance conversation quality. Their variant showed a 70% increase in average conversation length and a 30% boost in user retention. Similarly, Nextdoor experimented with AI-generated subject lines and saw a 1% improvement in click-through rates and a 0.4% increase in weekly active users after fine-tuning their reward function based on user feedback.
Given the unpredictable nature of LLM outputs, using power analysis to determine adequate sample sizes is critical. Additionally, clearly defined hypotheses - like "increase retention by 10%" - are far more actionable than vague goals like "improve user satisfaction."
Prompt Engineering Experiments
Prompt engineering involves systematically refining the inputs that guide an LLM’s responses. By experimenting with different phrasing, layouts, or contextual cues, teams can identify the most effective ways to achieve desired outcomes for specific use cases.
Key strategies include:
- Writing clear and specific prompts.
- Testing various delimiters or separators.
- Using step-by-step reasoning instructions.
- Creating scenarios or assigning personas.
- Specifying response formats for consistency.
Through iterative testing, teams can build a library of effective prompt patterns while discarding those that underperform. This process not only improves accuracy and consistency but also enhances user satisfaction by tailoring responses more effectively.
Data-Driven Model Adjustments
Once prompts are optimized, it’s essential to quantify their impact using targeted metrics. Traditional measures like BLEU or ROUGE are often too simplistic for the complex outputs of modern LLMs. Instead, many teams now rely on model-based evaluators.
For example:
- G-Eval uses language-based rubrics to assess subjective qualities like clarity, helpfulness, or tone.
- DAG scorers (decision tree-based) evaluate performance when specific success criteria are defined.
When working with retrieval-augmented generation (RAG) systems, focus on metrics like faithfulness, contextual precision, answer relevancy, and recall to gauge how well retrieved information is integrated. For agentic systems, prioritize metrics like tool accuracy and task completion rates.
It’s also crucial to monitor metrics related to hallucination and toxicity while tracking task-specific performance. This ensures improvements don’t compromise output quality. To avoid being overwhelmed, stick to a focused set of metrics - such as accuracy, latency, and a few custom indicators.
Interestingly, LLM judges like GPT-4 align with human evaluations over 80% of the time, making them invaluable for scalable assessments. Since explicit user feedback is rare - less than 1% of interactions yield direct feedback - implicit signals and automated evaluations play a critical role in validating improvements.
Finally, don’t overlook computational costs and token usage. The most accurate model isn’t always the best choice if it’s too resource-intensive. Balancing performance gains with operational efficiency is essential for a sustainable optimization strategy.
Advanced Feedback-Driven Optimization Methods
While basic feedback methods focus on streamlining adjustments, advanced techniques tackle more intricate challenges. These approaches include agent-specific improvements, real-time policy updates, and expert input, all aimed at addressing unique issues in LLM systems.
Multi-Agent Feedback Localization
In multi-agent systems, each agent is assigned a specific role, mimicking human problem-solving. When one agent underperforms, this method identifies the weak link and targets it for improvement.
Multi-agent feedback localization follows a two-step process. First, it detects underperforming agents and generates detailed explanations of their failures using textual feedback. Second, it uses these explanations to optimize the prompts guiding those agents’ actions.
"We propose a two-step agent prompts optimization pipeline: identifying underperforming agents with their failure explanations utilizing textual feedback and then optimizing system prompts of identified agents utilizing failure explanations." – Ming Shen, Raphael Shu, Anurag Pratik, James Gung, Yubin Ge, Monica Sunkara, Yi Zhang
An evaluation agent plays a key role here, monitoring intermediate results and providing immediate guidance for prompt adjustments. Studies show that multi-agent LLMs, when optimized through this method, can outperform individual agents by as much as 20% in complex tasks. In software development, this approach has been particularly effective in isolating and addressing specific failure points within development pipelines.
Building on agent-specific improvements, the next method uses LLMs to create smarter, more adaptable data augmentation strategies.
LLM-Guided Augmentation Policy Optimization
Data augmentation can significantly influence model performance, but traditional methods often apply generic transformations without tailoring them to the dataset or model. LLM-guided augmentation changes this by dynamically refining policies based on feedback.
This approach relies on an LLM to select and iteratively refine augmentation strategies. It adapts these strategies in real time, using performance metrics to guide adjustments, which minimizes the need for full model retraining before incorporating feedback.
The process involves the LLM analyzing dataset characteristics, model architecture, and prior training outcomes to recommend specific augmentation transformations. A feedback loop further fine-tunes these policies. For example, adaptive LLM-guided augmentation achieved an accuracy of 0.9738 on the Melanoma Cancer Image Dataset using ResNet18, showcasing its effectiveness.
Domain Expert Collaboration for Targeted Optimization
While automated strategies are powerful, expert collaboration brings a layer of precision that machines alone cannot achieve. Domain experts contribute critical contextual knowledge, enabling fine-tuned optimization through specialized interventions.
Experts improve LLM performance by refining prompts, curating targeted datasets, and analyzing feedback to address specific issues. A standout example is Salus AI’s project, which concluded in June 2024. By involving domain experts, they enhanced LLM performance in compliance tasks for marketing calls related to premium health screenings. Their efforts, which included prompt design, retrieval-augmented generation, and fine-tuning, raised performance from 80% to a range of 95%–100%.
For successful collaboration, an experimental framework is essential. This allows experts to analyze outputs, identify failure modes, and guide improvements. The process typically begins with prompt engineering to shape the LLM’s responses. Prompt versioning can then track changes and their effects. If further adjustments are needed, retrieval-augmented generation provides additional context, and fine-tuning with domain-specific datasets ensures targeted enhancements.
Best Practices for Real-Time Feedback Workflows
Turning raw feedback into meaningful improvements requires structured workflows that emphasize clarity, transparency, and efficiency. By applying these best practices, real-time feedback can effectively guide the optimization of large language models (LLMs).
Making Feedback Actionable and Context-Rich
The value of feedback often hinges on how specific and well-structured it is. Vague comments don't contribute much, but clear and detailed feedback can lead to immediate, impactful changes.
Clarity and structure are critical when creating systems to gather feedback. Use prompts that are precise and goal-oriented, specifying details like format, scope, tone, and length. This eliminates confusion and equips LLMs with the context needed to interpret and apply feedback successfully.
"Clear structure and context matter more than clever wording - most prompt failures come from ambiguity, not model limitations." - Lakera
Collect feedback right after interactions to ensure it reflects fresh insights. Combine simple quantitative ratings with concise qualitative notes for a balanced approach.
Custom properties, like user type or data source, can help identify trends and enable targeted improvements. Adding context, such as docstrings or standardized naming conventions, ensures feedback is consistent and actionable.
Maintaining Transparency and Traceability
Transparency is key to building trust and ensuring feedback leads to meaningful progress. Every feedback interaction should be recorded and accessible for analysis.
Version control is indispensable when implementing feedback-based changes. Keep track of all prompt versions and tag them appropriately. This allows you to revert to earlier versions if updates cause user dissatisfaction. Documenting the entire feedback lifecycle ensures a clear audit trail for debugging and decision-making.
Automated logging simplifies the process by capturing essential metadata, such as user context and system state. This reduces manual effort while preserving critical details for in-depth analysis and troubleshooting.
Using Platforms Like Latitude for Workflow Efficiency
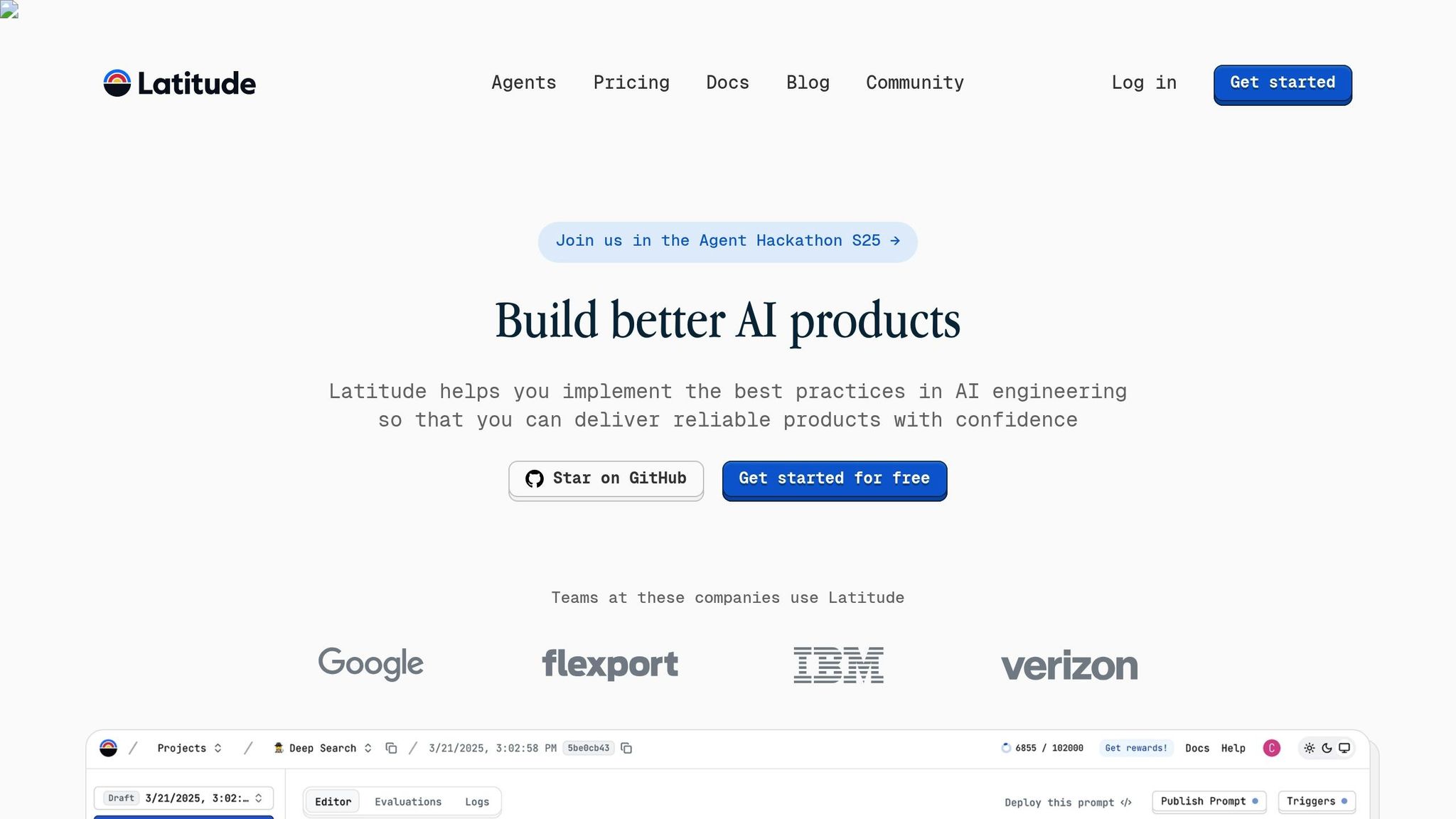
Platforms designed for feedback workflows, such as Latitude, can streamline and automate the process. Latitude offers tools for prompt engineering, evaluation, and deployment, enabling teams to collaborate effectively and optimize LLM prompts.
Here’s how a typical Latitude workflow operates:
- Start by creating a project to develop and refine prompts.
- Use the editor to write and test prompts with various inputs in the playground.
- Upload datasets and conduct batch evaluations to assess performance across scenarios.
- Deploy the refined prompt as an endpoint for seamless integration.
Latitude also automates logging by capturing context, output, and metadata with every prompt run. Advanced features - like parameters, snippets, logic, and version control - allow teams to manage prompts efficiently without needing custom infrastructure.
Collaboration tools within Latitude make it easy to scale prompt management, refine prompts with real or synthetic data, and monitor performance using methods like human-in-the-loop evaluations. The platform’s integration with production environments simplifies the deployment of new prompts, improving both performance and operational workflows.
Conclusion
Real-time feedback turns static large language models (LLMs) into dynamic systems that evolve and improve over time. This guide has explored a range of techniques - from straightforward feedback collection to more advanced multi-agent optimization methods - that help refine model performance through continuous iteration.
Feedback loops play a crucial role in narrowing the gap between what AI systems can do and what users expect. As Aarti Jha puts it, "No model is perfect, and user interactions provide a goldmine of insights into its strengths and weaknesses". To stay competitive, organizations should move away from static, one-time model deployments and adopt workflows that continuously incorporate real-world feedback.
The importance of observability grows as LLMs are scaled in production environments. According to Snorkel AI, "LLM observability is no longer a luxury - it is a necessity for enterprise GenAI success". Monitoring key factors like accuracy, safety, compliance, and relevance ensures teams can quickly identify and address issues like model drift before they impact performance.
The strategies outlined here offer organizations practical tools to improve LLM performance through actionable feedback. By leveraging these methods, businesses can address the challenges of deploying and maintaining LLMs effectively.
Platforms like Latitude simplify the integration of real-time feedback by offering tools for prompt engineering, evaluation, and deployment. These tools help engineers and experts refine models based on direct user input, making the optimization process more efficient.
Looking ahead, the future of LLM optimization depends on continuous evolution. As user needs shift, models must adapt to stay relevant. By applying the real-time feedback techniques discussed in this guide and utilizing specialized platforms for workflow management, businesses can transform general-purpose AI into tailored solutions that address specific challenges and drive meaningful results.
FAQs
How does real-time feedback boost the performance of large language models compared to traditional fine-tuning?
Real-time feedback gives large language models (LLMs) the ability to adjust and refine their responses on the fly, improving accuracy, relevance, and understanding of context during deployment. Unlike traditional fine-tuning - which depends on fixed datasets and occurs only at specific intervals - real-time feedback allows for continuous updates driven by user interactions.
This dynamic process helps LLMs tackle biases, enhance response quality, and align better with real-world scenarios, ensuring they remain practical and responsive in everyday applications.
What are the key challenges of implementing real-time feedback systems for LLM optimization, and how can they be solved?
Managing real-time feedback systems for optimizing large language models (LLMs) isn't without its hurdles. One of the biggest challenges lies in handling intense computational demands while still delivering feedback that’s both timely and precise. Delays in feedback can directly affect performance. There’s also the risk of overfitting, where the model becomes too tailored to specific data, or exposure to adversarial inputs, which can weaken its reliability.
To tackle these issues, organizations can take a few practical steps. They can focus on streamlining inference processes to reduce computational strain, implement efficient monitoring tools to track performance without overwhelming resources, and develop adaptive feedback mechanisms that carefully balance updates with available system capacity. These approaches help keep the model effective and scalable without pushing the infrastructure to its limits.
What are the best ways to measure how real-time feedback improves LLM performance?
To assess how real-time feedback influences the performance of large language models (LLMs), organizations often rely on a mix of automated metrics and human evaluations. Some important metrics to consider are relevance, accuracy, semantic similarity, and identifying hallucinations. Additionally, evaluating fluency, coherence, and task-specific accuracy offers deeper insights into model performance.
Developing diverse and representative datasets for testing, along with employing rank-based or multi-modal evaluation methods, can help refine these assessments. These strategies allow for ongoing monitoring and fine-tuning, ensuring LLMs are well-suited for practical, real-world use.
